Kafka: a Distributed Messaging System for Log Processing (2011)
论文引用量:744 (截止至 2020-03-15)
Kafka 是开发者耳熟能详的开源项目,它已经成为近年来互联网公司必不可少的基础组件。Kafka 得名于作家 Franz Kafka,大概是因为二者都比较擅长写日志 : )。它孵化于 LinkedIn 内部,在 2011 年被捐赠给 Apache 基金会,2012 年末正式从 Apache Incubator 中毕业。本文于 2011 年发表于 NetDB workshop,如今原文的三位作者,Jay Kreps、Neha Narkhede 以及 Jun Rao 一同离开 LinkedIn,创立 Confluent.io,提供基于 Kafka 的企业级 Event Streaming Platform 服务。
除了翻译论文原文的核心内容之外,本文也会补充一些论文发表当时还未问世的话题,如 replication,exactly-once delivery 等。
Introduction
在规模较大的互联网公司中,每天都会产生大量的日志数据,如:
- 用户事件:登录、访问、点击、分享、评论、搜索
- 性能指标:时延、错误、QPS
- 机器指标:CPU、Memory、Network、Disk Utilication
这些日志数据常常被用于离线分析,帮助公司了解用户、产品,帮助开发者了解系统、服务。在初期,每当 LinkedIn 内部有服务需要使用这些日志数据时,研发人员就需要写新的数据传输脚本或在线传输逻辑,久而久之,内部服务的拓扑图就出现了类似完全图的形状:
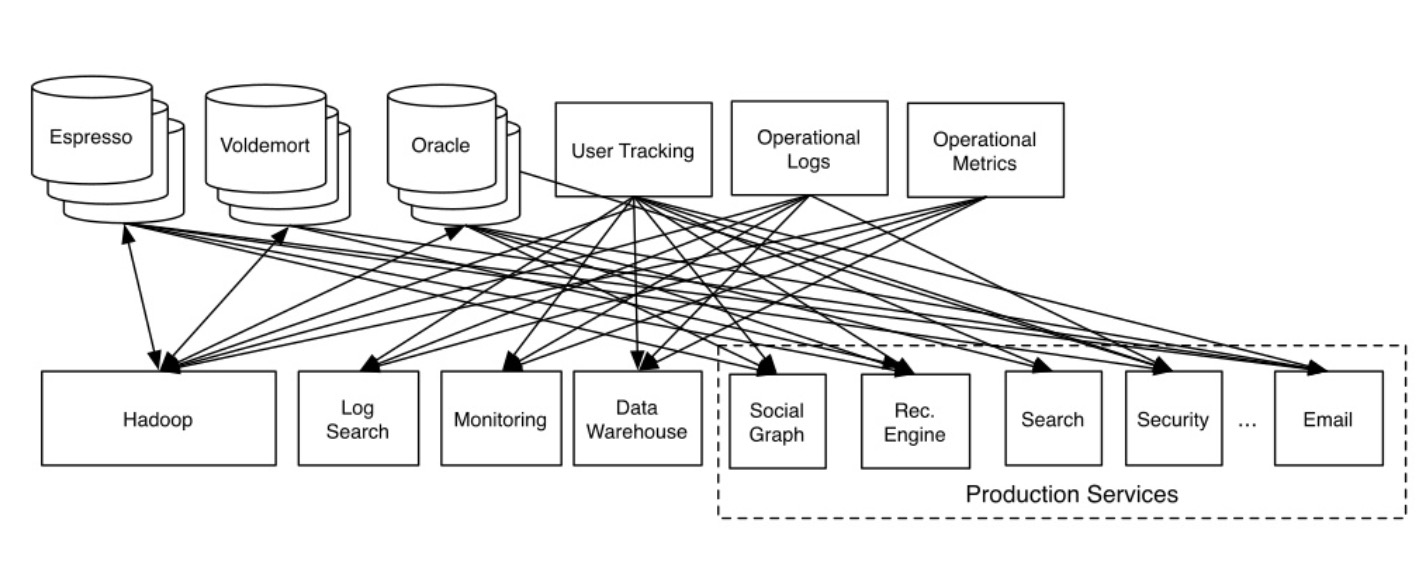
这种拓扑图对分布式系统很不友好,不仅可能造成网络资源浪费,维护成本也极高。有 DRY 精神的工程师肯定无法忍受这样的架构,这时就需要有一个服务能将日志数据的消费和生产隔离:
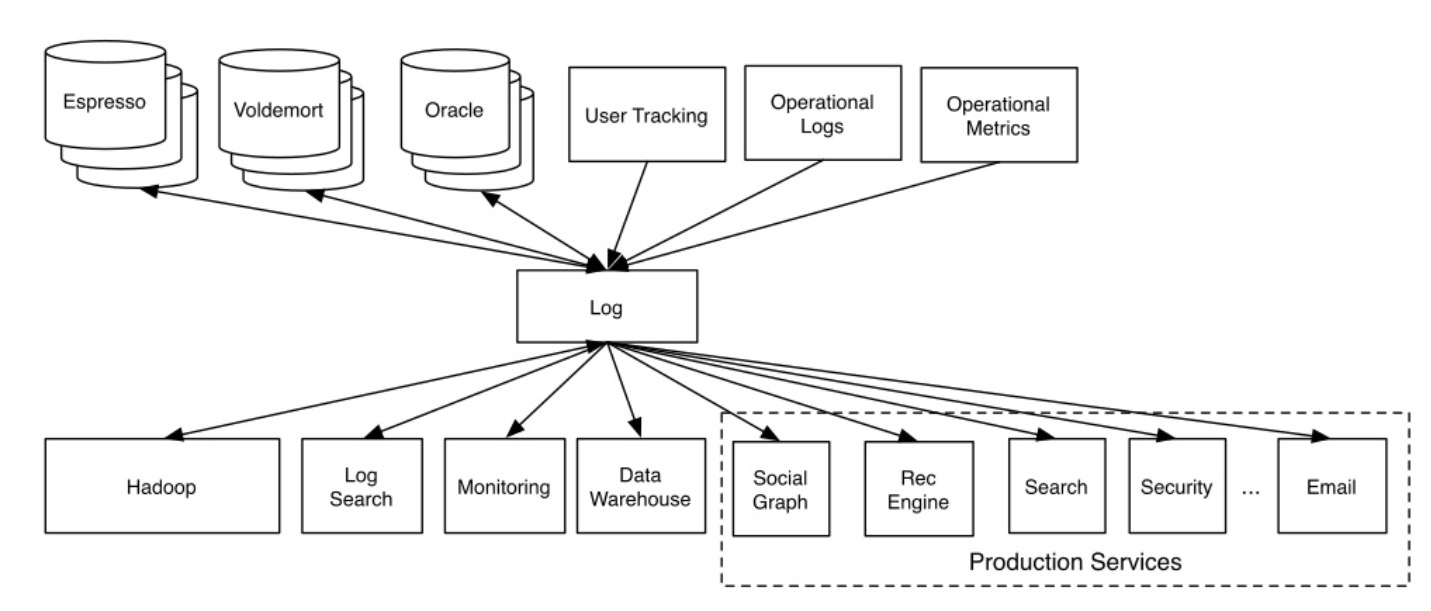
最近 (2011 年),对日志数据的使用趋势在改变,这些日志被逐步用于实时地改善在线服务的一些功能,如:搜索相关性、推荐算法、网络安全等。由于日志数据的体量超过实际数据好几个数量级,实时或准实时地使用这些数据对日志系统本身也是不小的挑战。
综上所述,我们可以总结 Kafka 的核心设计要求:
- Publish/Subscribe
- Large throughput
- Delays in a few seconds
也许你已经察觉,Kafka 是介于日志系统与消息系统之间的存在,你将在其内部概念和设计中窥见二者的影子。
Kafka Architecture and Design Principles
Overview
在介绍 Kafka 的架构和设计原则之前,先了解几个概念:
- Topic:单个类型的日志 (消息) 流
- Producer:负责将消息发布到 topic 中
- Broker:被发布的消息将被持久化到一个集群中,broker 是集群中的单个实例
- Consumer:按需订阅 topic,主动从 brokers 中拉取数据
- Conumser Group: 消费组,由一个或多个 consumer 构成,是订阅 topic 的最小单位
- Message:字节数组,支持任意的序列化/反序列化方案
整体架构如下图所示:
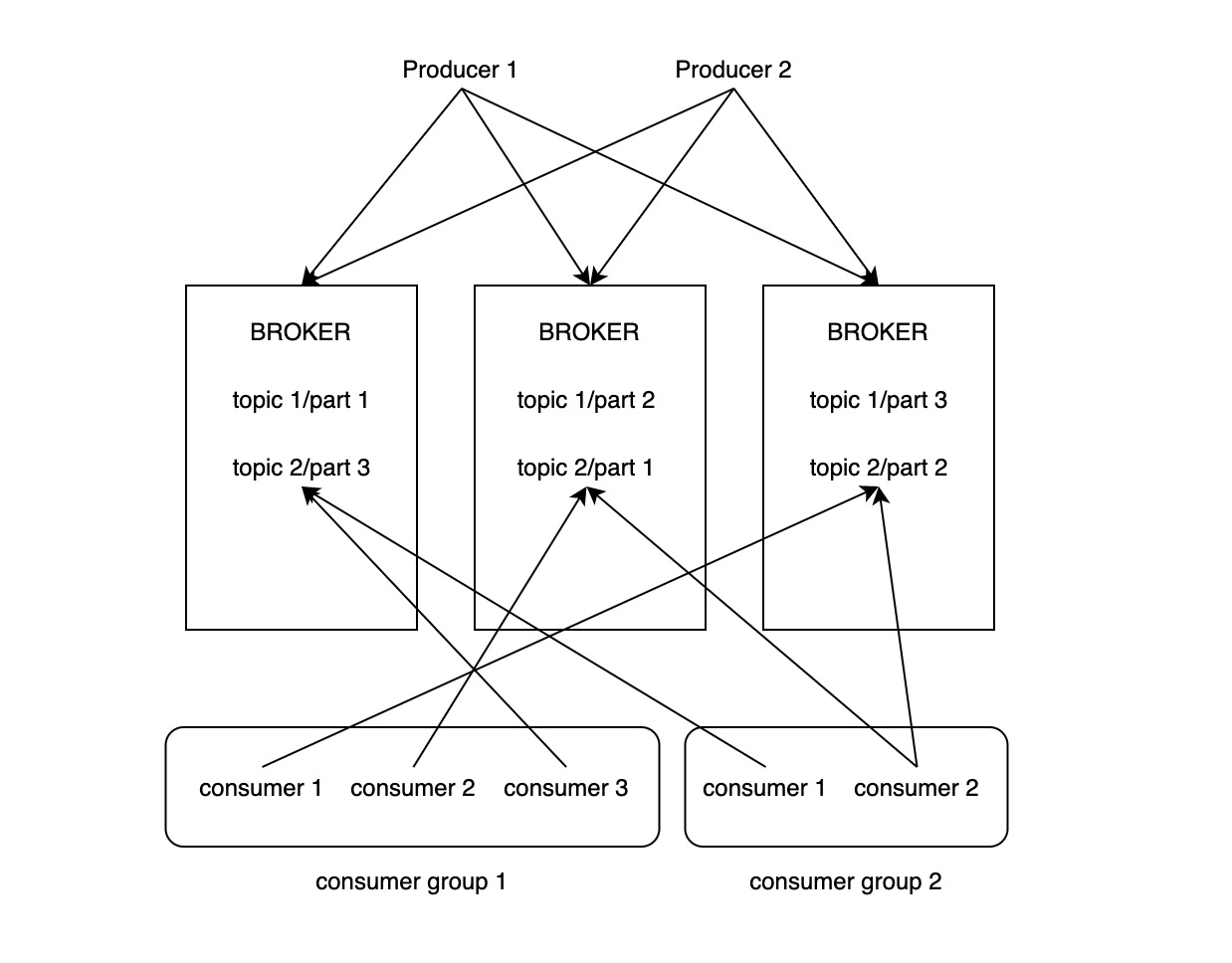
producer 将消息发布到 broker 中的某个 topic 上,每个 topic 被划分成多个 partition,存储在不同的 broker 上。consumer group 中的 consumer 订阅某个 topic 后,就可以从 broker 中消费消息。如果没有 producer 发布新的消息,consumer 将阻塞等待而不会停止。topic 中的单条消息只会被 consumer group 中的单个 consumer 消费,而不同 consumer group 将消费到同一个 topic 中的所有消息。
producer 可以在没有 consumer 订阅时发布消息,consumer 也可以在没有 producer 发布消息时消费消息 (阻塞等待),二者之间相互隔离。通过将 topic 数据分片,Kafka 天然地获得了横向扩展性,也在设计上为高吞吐打下基础。
Efficienty on a Single Partition
本节介绍 LinkedIn 团队在提高系统整体性能上做出的 3 个设计决策。
Simple Storage
Kafka 的 storage layout 设计得很简洁:每个 partition 是一个逻辑日志文件,如下图所示:
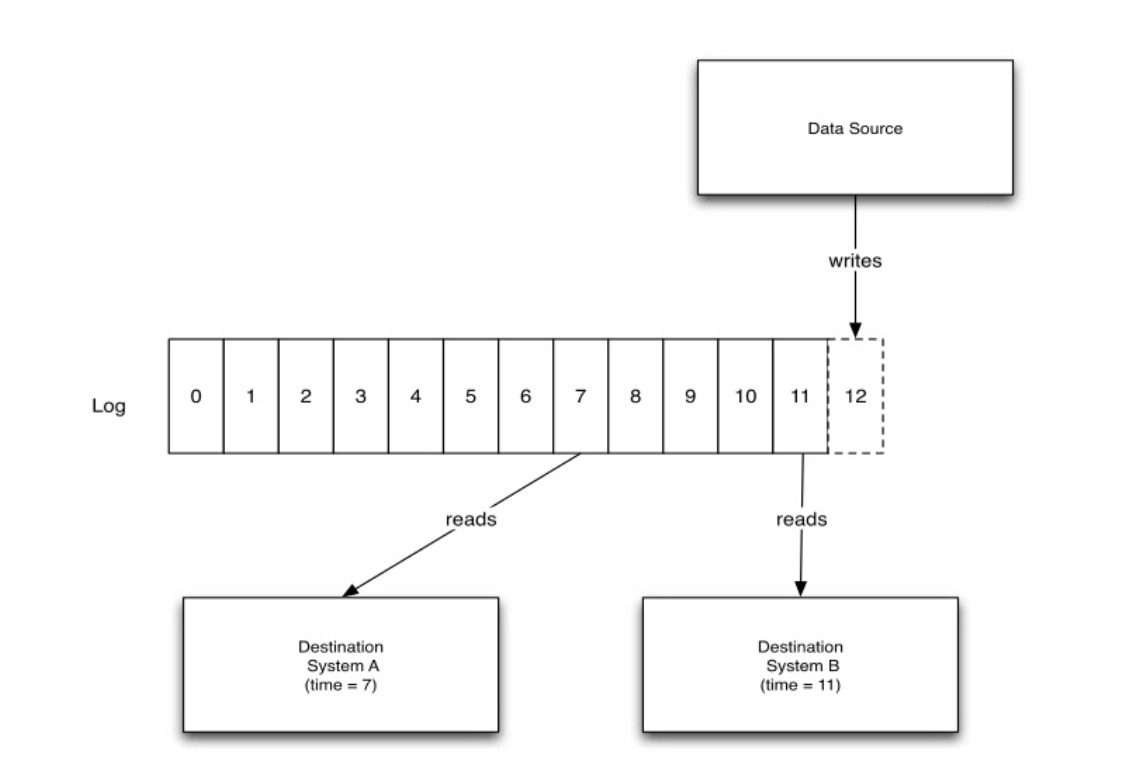
producer 不断地往 partition 的尾部追加消息,与此同时不同的 consumer 可以从日志文件中的任意位置开始消费数据。每个逻辑日志文件在物理上由一组大小基本相同(如 1GB)的 segments 文件构成,示例如下:
1 | topic-0-partition-0 |
每个 segment 文件以其中第一条消息的 offset 命名:
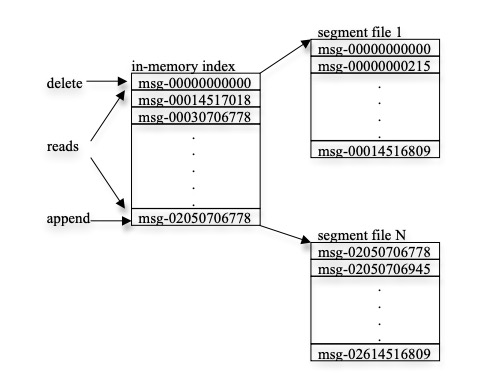
每当 producer 生产一条消息到 kafka 中,相应的 broker 就将消息追加到当前最新的 segment 文件末尾中。为了提升文件 I/O 效率,新追加的数据只有在达到一定大小或经过一定时间后才会批量落盘,而只有在数据正式落盘后,consumers 才有可能消费到相应数据。segment 中的消息没有显式 id,但每条消息可以用其 offset 来唯一标识,因此实际上 offset 扮演了索引和 id 双重角色。
尽管每个 topic 会被分成多个 partition (配置中指定),在同一个 consumer group 内部,一个 partition 只会被一个 consumer 消费。consumer ack 一个 offset 就意味着它已经成功消费所有在那之前的消息。从实现层面上看:
- consumer 先向相应的 broker 发送异步的数据拉取请求,参数包括下一条消息的 offset 和想要获取的数据量
- 每个 broker 在内存中将每个 segment 的起始 offset 排好序。broker 收到数据拉取请求后,快速定位目标 segment 文件,通过相应的 index 文件可以快速找到目标数据,读取后返回给 consumer
- consumer 收到消息后,计算下一条消息的 offset 用于下一次数据拉取请求
将每个 partition 分成大小相同的 segments 文件对于 retention policy 非常友好,每次清理过期数据时直接删除文件即可。
Efficient Transfer
Kafka 的 producer 可以在一次发布请求中发送多条消息,consumer 同样可以在一次拉取请求中获取多条消息。尽管表面上看来 producer 在一条一条生产 (单条生产 API),consumer 在一条一条消费,但通常为了提高效率,Kafka 的 sdk 会批量地处理数据。除此之外,producer 在发送消息前,数据会被压缩,consumer 接收到消息后,数据才会被解压,因此整个过程中不仅节约了带宽,也节约了持久化存储空间。
Kafka 的存储层不会显式地在内存中缓存日志数据,而是将相应的工作交给文件系统的 page cache,其主要好处在于避免 double buffering,同时在 broker 进程重启时不需要预热 cache,这个设计决定也让 kafka 团队减少对内存垃圾收集等方面的关注。在大多数情况下,consumer 不会滞后 producer 太多,这意味着它们访问的数据有时间局部性,而这与操作系统 cache policy 的优化目标相符。
通常数据从 segment 文件传输到客户端 socket 需要 4 个步骤:
- 将数据从文件中读入 OS 的 page cache
- 将数据从 page cache 中复制到应用层缓存
- 将应用层缓存中的数据复制到 kernel buffer
- 将 kernel buffer 中的数据写出到客户端 socket
整个过程包含 4 次数据复制和 2 次系统调用。在 Linux/Unix 系统中存在一个 sendfile API,它能够直接将持久化存储中的文件数据传输到 socket 上,直接省略了 2、3 两步,节省 2 次数据复制和 1 次系统调用,利用该系统调用 Kafka 进一步优化了数据传输效率。
Stateless Broker
与其它消息系统不同,Kafka broker 并不会记录 consumer 消费的 offset,因此可以认为 Kafka broker 没有状态。该设计决定降低了 Kafka broker 本身的复杂度和成本。那么 Kafka 如何清理消息?考虑到多个 consumers 的消费进度不一样,如果要动态控制就会过于繁琐。最终 Kafka 使用的方案是只保留过去 7 天 (配置) 的数据,如果 consumers 来不及消费就只能承受数据丢失的损失。
这种设计还有一个副作用,consumer 在必要的时候可以重新消费数据。只要 consumer 愿意,在拉取数据时修改 offset 即可,在一些 ETL 场景下这种功能大有用武之地。如果 Kafka 没有选择让 consumer 拉取数据,而是让 broker 推送数据到 consumer,那么这种功能将很难实现。
Distributed Coordination
在协调 producer 与 consumer 之间的交互行为上,Kafka 团队做了两个设计决定。
决定 1:Kafka 中的并行最小单元是 partition
这意味着在任意时刻,一个 partition 内部的数据只能被 consumer group 中的某个特定 consumer 消费。如果我们允许 consumer group 中的多个 consumer 同时消费一个 partition,那么系统就需要引入锁机制和各个 consumer 的消费状态信息。将并行的最小单元限制成 partition,可以极大地减少代码逻辑和维护成本,不同 consumer 之间只需要在发生数据 rebalance 的时候协调消费行为,大部分情况下则无需考虑其它 consumer 的行为。因此如果想让数据更均匀地分配给 consumer group 中的不同 consumers,用户可以在配置 topic 的时候设定更大的 partition 数量。
举例如下:假设某 consumer group 有 3 个 consumers,如果一个 topic 被分成 4 个 partition,那么 consumer group 内部的分配方式为 [2, 1, 1];如果一个 topic 被分成 14 个 partition,那么 consumer group 内部的分配方式为 [5, 4, 4],可以看出后者的分配比前者更均匀。
决定 2:没有 master 节点
Kafka 是将全局共享的数据托付给 Zookeeper 保管,因此 brokers 中不存在 master 节点的概念,因此无需考虑 master 故障的问题。Zookeeper 承担的主要职责包括但不局限于:
- 检测 brokers 和 consumers 的增减,即注册与发现
- brokers 与 consumers 变化时触发数据 rebalance
- 维护消费关系,即 xx consumer 消费 xx partition;记录消费进度,即保存 offset;
当 broker 或者 consumer 启动时,二者的信息将被分别存储在 Zookeeper 的 broker registry 和 consumer registry 中。broker registry 包含 broker 的 host、port、以及其中存储的 topics 和 partitions 集合信息,如:
1 | // 路径:/brokers/ids/[brokerId] |
consumer registry 包含 consumer 的所属的 consumer group 及其订阅的 topics 信息,如:
1 | // 路径:/consumers/[groupId]/ids/[consumerId] |
每个 consumer group 都有一个 ownership registry,用来记录某 consumer 正在消费的 partition 信息,如:
1 | // 路径:/consumers/[groupId]/owners/[topic]/[partitionId] -> string (consumerId) |
每个 consumer group 还有一个 offset registry,用来记录 consumer 消费 partition 的 offset 信息,如:
1 | // 路径:/consumers/[groupId]/offsets/[topic]/[partitionId] -> long (offset) |
这些路径中,broker registry、consumer registry 以及 ownership registry 都是临时 (ephemeral) 路径,而 offset registry 是持久化 (persistent) 路径。如果 broker 发生故障,所有存储于它之上的 partitions 都会从 broker registry 中删除;如果 consumer 发生故障,所有它拥有的 partition 信息也将被删除。每个 consumer 都会监听 broker registry 和 consumer registry 的变化,一旦 broker set 和 consumer group 发生变化,它们能立即做出相应改变。
在 consumer 启动或从 watcher 中接收到 broker/consumer 的变化信息时,consumer 会启动一个 rebalance 进程来重新确定它将消费的 partitions。其算法如下面的伪代码所示:
1 | // rebalance: 针对某个 topic,为 consumer 重新分配 partitions |
当 consumer group 中存在多个 consumers 时,它们收到 broker/consumer 变化通知的时间点可能不一样,因此有可能先得到的某个 consumer 会尝试去获取已经有 owner 的 partition,因为后者尚未接到通知。当这种情况发生时,前者会放弃自己拥有的所有 partitions,等待一小段时间后再次执行 rebalance 的逻辑。在实践中通常经过少量的重试后就能够进入稳定状态。
当新的 consumer 创建时,offset registry 中尚未有任何记录,consumers 可以选择从最小或最大 offset 开始消费,Kafka 的 SDK 提供相应支持。
Delivery Guarantees
At-least-once Delivery
在论文发表时,Kafka 只能提供 at-leat-once delivery 的保证。在大多数情况下,消息只会被每个 consumer group 消费一次。然而,当某个 consumer 进程意外崩溃时,同一个 consumer group 的其它 consumers 将可能消费到重复消息。如果实际应用场景需要保证 exactly-once 的语义,那么该应用必须自己利用 offset (作为 id) 或其它信息构建去重逻辑。
Kafka 保证从单个 partition 读取的消息顺序,但在 topic 级别上不保证任何顺序。为了避免日志数据被破坏,Kafka 在日志中的每条消息上都存储了 CRC,如果 broker 出现 I/O error,Kafka 将自动运行恢复程序,将与 CRC 不一致的消息删除。同时,CRC 也可以在应用层上检查是否有网络传输错误。
Exactly-once Delivery
自 0.11.0.0 版本后,Kafka 开始提供 exactly-once delivery 的支持。从 producer 生产消息到 consumer 消费消息,在顺利的情况下每条消息只会被消费一次。但云原生环境下任何事情都可能发生:
- broker 故障:高可用性和持久性都是 Kafka 设计目标,通过阅读 replication 一节,就能知道一个大小为 f 的 Kafka 集群能够容忍 f-1 个 broker 发生故障。
- producer-to-broker RPC 调用失败:producer 向 broker 发送消息后,收到 ack 才能确认消息发送成功。但没有收到 ack 并不意味着 broker 没有成功将消息写入本地日志文件,中间的任何环节都有可能出错。而对于 producer 来说,没有收到 ack 只能重试,如果在此之前消息已经成功写入,Kafka 上就可能出现重复数据,相应地 consumer 就会消费两次相同的数据。
- client 故障:producer 和 consumer 本身也可能发生故障。在 broker 看来,producer 可能忽然失联,或是因为网络分区 (使后者成为 zombie producer),或是因为 producer 崩溃。此时如果另一个 producer 进程以相同的身份注册到 Kafka,就可能出现两个 producer (网络分区恢复) 以相同的身份发送数据,为了正确性,Kafka 要能够识别 zombie producer。对 consumer 来说也是如此,在 consumer 发生故障时,让新的/其余 consumer 从上个 consumer 消费结束的位置开始继续消费。这意味着所有 consumer 消费的 offset 信息都必须与实际消费的结果保持一致。
解决了 broker、consumer、producer 各自内部故障,以及 broker/consumer、broker/producer 之间的通信故障,才使真正提供 exactly-once delivery 支持称为可能。需要注意的是,exactly-once delivery 本身并不是仅 Kafka 本身就能实现,用户完全可以重复生产或重复消费,因此完整的 exactly-once delivery 语义支持是双方共同努力的结果,以下的特性仅是 Kafka 一方所做的努力,使用方需要充分了解并正确使用才能最终实现 exactly-once delivery。
Idempotence: Exactly-once in order semantics per partition
如果能够让 producer-to-broker RPC 请求满足幂等性,就可以解决 Kafka 收到重复数据的问题。解决方案和 tcp 利用 sequence number 去重的逻辑类似,只要 producer 为每条消息带上一个递增的 sequence number,Kafka 就能够根据 sequence number 去重。
Transactions: Aomic writes across multiple partitions
Kafka 的 Transactions API 支持 2PC 协议,producer 能够批量地发送消息到不同 partitions 上,同时保证所有消息及 offset 信息写入的原子性,这里不详细展开,详情可见这篇博客 Transactions in Apache Kafka。
如何利用二者实现完整的 exactly-once delivery,可以参考这篇博客 Processing guarantees in Kafka。
Replication
如果一个 broker 崩溃,存储在上面的数据将不可用,要提高服务的可用性和持久性,就需要引入 replication。从 0.8 版本开始,Kafka 已经支持集群内部数据复制的功能。
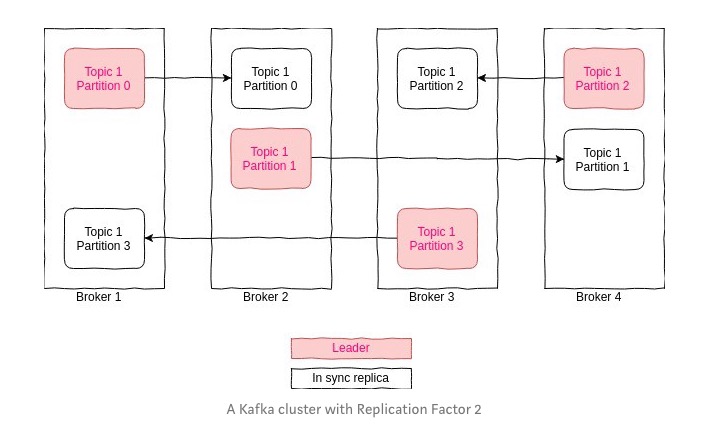
如上图所示,从用户的角度来看 replication:根据 replication factor 的设置,每个 topic 的每个 partition 将拥有若干个 replicas,其中有一个是 leader,负责处理所有读写请求,剩下的是 replicas,留作备用。replication 模块主要解决的两个问题是:
- Replica Assignment
- Data Replication
Replica Assignment
Replica Assignment 的目的很简单:将 replicas 均匀地分布到不同的 broker 上,步骤如下:
- 随机选择某个 broker 为起点,使用 round-robin 的方式将 partition 分配给不同的 broker,这些 broker 将成为相应 partition 的 leader
- 针对每个 partition,将其 replicas 渐进地(
)平移分配到 leader broker 之后的 brokers 中。
假设有 5 个 broker (broker0-4),10 个 partition (p0-9),假设选择 borker0 为起点:
根据公式, p0-p4 的 replica 平移 offset = 1;p5-p9 的 replica 平移 offset = 2,具体分配如下:
| broker0 | broker1 | broker2 | broker3 | broker4 |
|---|---|---|---|---|
| p0 | p1 | p2 | p3 | p4 |
| p5 | p6 | p7 | p8 | p9 |
| - | p0 | p1 | p2 | p3 |
| p4 | p5 | p6 | p7 | |
| p8 | p9 | p0 | p1 | p2 |
| p3 | p4 | p5 | p6 | |
| p7 | p8 | p9 | - | - |
(NOTE:这里不理解为什么偏移量要递增,不过源码确实是这么实现,保持 offset = 1 理论上更平衡)
Data Replication
数据复制通常有两种策略:primary-backup replication 和 qorum-based replication。无论选择哪种策略,总是有一个 replica 需要承担 leader 的角色,剩下的 replica 则为 follower。所有写操作首先经过 leader,再由 leader 传播给 followers。
在 primary-backup 策略中,leader 在返回响应给 client 之前,必须等待数据写入所有 replica 中。如果有一个 replica 发生故障,leader 就会将它从 group 中剔除,并将数据写入剩下的 replicas 中。发生故障的 replica 在恢复后可以请求同步数据,当他与大家保持同步后可以重新回到 group 中。如果 group 中有 f 个 replicas,primary-backup 策略可以容忍 f-1 个 replica 发生故障。
在 qorum-based 策略中,leader 在返回响应给 client 之前,只需等待数据写入大多数 replica 中,任何 replica 发生故障都不会引起整个 replica group 的大小变化。如果 group 中有 2f+1 个 replicas,quorum-based 策略可以容忍 f 个 replica 发生故障,如果 leader 发生故障,则至少需要 f+1 个 replicas 来选举新的 leader。
我们简单对比一下二者的特点:
| primary-backup | quorum-based | |
|---|---|---|
| write latency | 高:任意 replica 延迟都能使整体延迟上升 | 低:只要不出现多数 replica 同时延迟上升 |
| fault tolerance | 高:能容忍更多 replica 故障 | 低:只能容忍少数 replica 故障 |
鉴于通常数据复制的最佳实践是 3 个备份,Kafka 团队最终选择 primary-backup 复制策略。
Writes
producer 想要发布消息到某 partition 上时,先从 Zookeeper 上获取 partition leader,然后直接将消息发送给后者。leader 将消息写入本地日志。partition followers 通过 socket channel 不断地从 leader 处获取最新的消息,获取消息的顺序与 leader 的保持一致。follower 将消息写入本地日志后,回复 ack 给 leader。一旦 leader 获得所有 ISR (In Sync Replicas) 的回复后,该消息才正式提交 (committed),leader 提高 HW (high watermark) 后将 ack 返回给 producer。为了提升性能,每个 follower 在将消息写入内存后就返回 ack 给 leader,因此对于 commited message,Kafka 只保证这条消息写入多所有 replicas 的内存中。Kafka 团队认为通过 replication 提供的持久化保证比消息落盘的保证更强,也能在性能和持久性上取得更好的平衡,当然用户也可以开启 fsync,保证消息落盘后才认为是正式提交。
Reads
consumer 读数据时,只会从 partition leader 上读取,最多能读到最新 commited 消息所在的 offset。