分布式锁方案:效率与正确的权衡
提到分布式锁,很多人也许会脱口而出 “redis”,可见利用 redis 实现分布式锁已被认为是最佳实践。这两天有个同事问我一个问题:“如果某个服务拿着分布式锁的时候,redis 实例挂了怎么办?重启以后锁丢了怎么办?利用主从可以吗?加 fsync 可以吗?”
因此我决定深究这个话题。
备注:本文中,因为信息源使用的术语不同,Correctness 与 Safety 分别翻译成正确性和安全性,实际上二者在分布式锁话题的范畴中意思相同。
Efficiency & Correctness
如果想让单机/实例上的多个线程去执行同一组任务,为了避免任务被重复执行,使用本地环境提供的 Lock 原语即可实现;但如果想让单机/实例上,或多机/实例上的多个进程去抢同一组任务,就需要分布式锁。总体来说,对分布式锁的要求可以从两个角度来考虑:
- 效率 (Efficiency):为了避免一个任务被执行多次,每个执行方在任务启动时先抢锁,在绝大多数情况下能避免重复工作。即便在极其偶然的情况下,分布式锁服务故障导致同一时刻有两个执行方抢到锁,使得某个任务被执行两次,总体看来依然无伤大雅。
- 正确性 (Correctness):多个任务执行方仅能有一方成功获取锁,进而执行任务,否则系统的状态会被破坏。比如任务执行两次可能破坏文件结构、丢失数据、产生不一致数据或其它不可逆的问题。
以效率和正确性为横轴和纵轴,得到一个直角坐标系,那么任何一个 (分布式) 锁解决方案就可以认为是这个坐标系中的一个点:
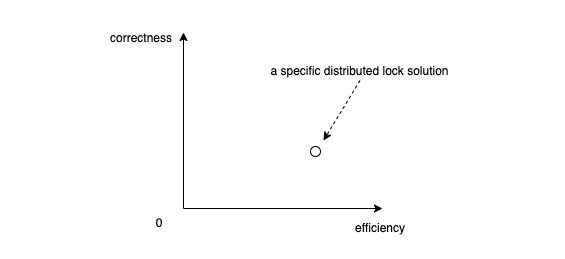
Solutions
在进入分布式锁解决方案之前,必须要明确:分布式锁只是某个特定业务需求解决方案的一部分,业务功能的真正实现是业务服务、分布式锁、存储服务以及其它有关各方共同努力的结果。
本节分别讨论侧重效率和侧重正确性的两类解决方案,并给出相应的实现思路。
For Efficiency
如果任务的执行具备幂等性,或即使少量任务重复执行对整体功能没有影响,开发者就可以选择侧重效率的解决方案。
Design Requirements
侧重效率解决方案的设计要求可以概括如下:
- High Efficiency:抢锁、释放锁操作高效 (这里暂不设定具体的 QPS)
- Weak Safety:在绝大多数时刻,只要持有时间不超过 TTL,只能有一个 client 能取到锁
- Liveness
- Deadlock free:如果 client 抢锁后崩溃或者出现网络分区,其它 client 不能永远等待下去
- No Fault tolerance/Availability:不需要容错机制,不需要高可用保证
Implementation: Single Redis Instance
如果你面对的业务场景侧重效率,那么基于单实例 redis 的解决方案就是你的菜。redis 是内存数据库,请求的执行效率基本能满足要求。下面介绍的就是 redis 官方提供的解决方案缩略版,你也可以阅读原文。
Lock/Unlock
1 | -- Lock |
resource_name 是分布式锁的 id,它的唯一可以保证只有一个 client 可以 SET 成功;NX 表示仅在 resource_name 在 redis 中不存在时才执行,用于保证 Week Safety;PX 30000 表示 30 秒超时,用来保证 Deadlock free;my_random_value 是每个取锁请求的 id,释放锁的逻辑如下:
1 | -- Unlock.lua |
释放锁时,当且仅当入参与之前加锁时用的 my_random_value 相等时才删除相应的键值对。my_random_valu 的唯一可以保证释放锁 (unlock) 操作的安全性,锁不会被误释放、获取、恶意释放。一种误释放的场景如下图所示:
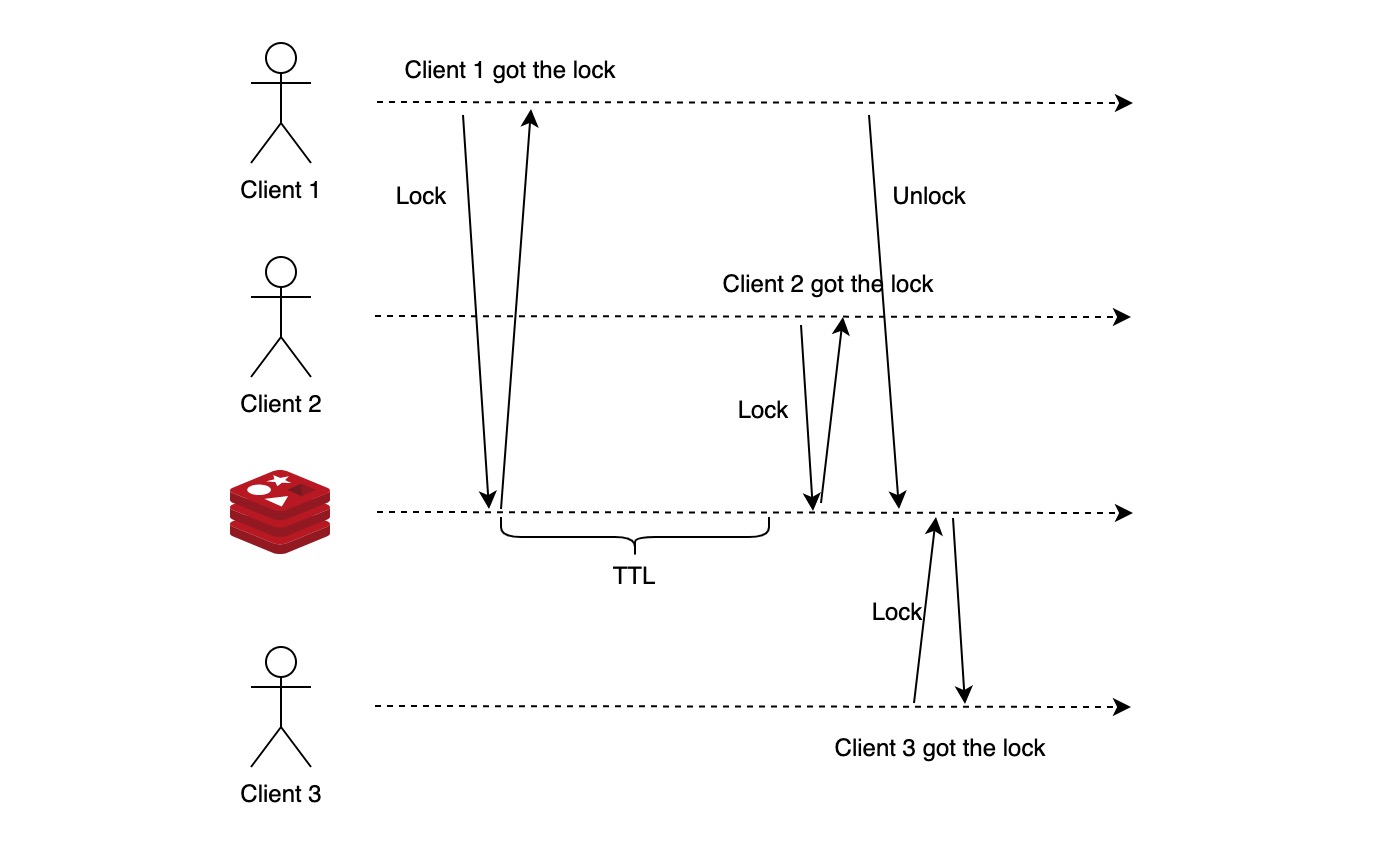
- client 1 获取锁成功。因为某种原因,如网络延迟、GC 导致 client 1 执行任务时间超过 TTL
- client 2 获取锁成功
- client 1 完成任务,执行释放锁操作,此时如果没有 my_random_value,client 2 获取的锁将被误释放
- client 3 获取锁成功
此时,client 2 和 3 都认为自己取锁成功,违背了 safety。
Fault Tolerance & Availability
如果只有单实例,挂了以后锁服务就立即不可用。如果实例故障后立即重启,则锁可能立即被抢走,锁的安全性无法保证。
For Correctness
如果任务的执行不具备幂等性,且系统可能因为任务重复执行陷入麻烦,开发者就必须考虑侧重正确性的解决方案。
Design Requirements
侧重正确性解决方案的设计要求概括如下:
- Strong Safety: 在任意时刻,只要持有时间不超过 TTL,只能有一个 client 能取到锁
- Liveness
- Deadlock free:如果 client 抢锁后崩溃或者出现网络分区,其它 client 不能永远等待下去
- Strong Fault Tolerance & Availability:高容错、高可用
Implementation: Concensus Service
在云原生环境下,一个系统要做到高容错、高可用,就必须能够横向扩容,横向扩容的结果就是任何在单机/实例下证明有效的算法都要能够合理地迁移到多实例中。以单实例版 redis 分布式锁为例,要迁移到多实例上,拿掉 Single Point of Failure (SPOF) 就意味着失去 Single Source of Truth (SSOT),详细讨论见 Redlock & Debate 一节。在多实例环境下要实现 Strong Safety,就必须引入经过理论与实践检验的共识算法,如 Raft、Viewstamped Replication、Zab 以及 Paxos,这些算法在 asynchronous model with unreliable failure detectors (翻译成人话就是算法的正确性不依赖系统中任何事件发生时间) 的故障模型下,依然能在一定故障 (少于半数节点故障) 存在的情况下保证系统对一些信息达成共识。
本节就不 (mei) 详 (neng) 细 (li) 展开对 Concensus Service 的讨论,感兴趣的可以阅读 DDIA 的 Consistency & Consensus 一节,或者翻阅相关论文。
The Whole Story
理想状况下,开发者利用侧重正确性解决方案的最终目的是:在任何情况下每个任务仅被执行一次。仅靠侧重正确性的分布式锁方案还不够。考虑这样一个场景:
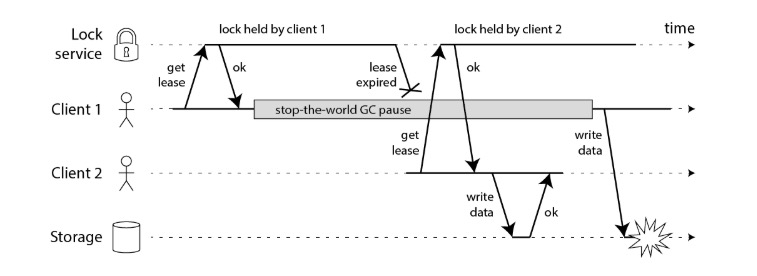
- client 1 获取锁成功,但不巧遇到了 stop-the-world GC 暂停,导致锁过期
- client 2 获取锁成功,执行任务,并成功写入结果到 storage 中
- client 1 GC 结束后,执行任务,并成功写入结果到 storage 中
同样的任务重复执行,client 2 写入的数据被 client 1 写入的数据覆盖,出现更新丢失 (lost updates)。上述场景中,lock service 完全按照要求运行,但结局感人肺腑。
但如果 lock service 能和 storage 配合起来,就能解决更新丢失问题:
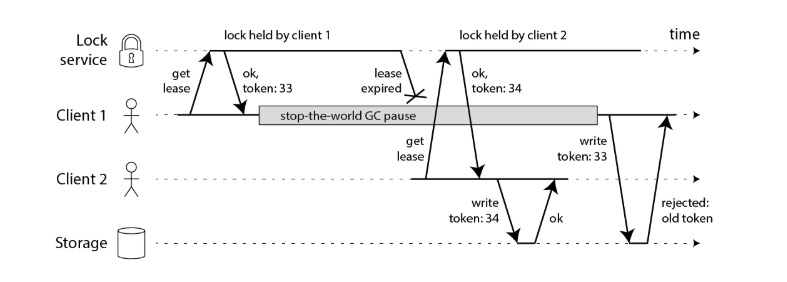
- client 1 获取锁成功,同时获得单调自增 token = 33,遇到 stop-the-world GC 暂停,导致锁过期
- client 2 获取锁成功,同时获得单调自增 token = 34,执行任务,并成功写入 storage
- client 1 GC 结束后,执行任务,写入 storage 时,后者发现 token 比最新写入的 token 小,拒绝执行
从上面这个例子可以看出,拥有一个侧重正确性的分布式锁解决方案仅仅是一个完整的任务执行去重方案必要条件。这与消息系统中的 exactly-once delivery guarantee 十分类似,exactly-once 语义的正确实现,需要参与各方的正确合作才可能实现。
Redlock & Debate
单实例 redis 架构上的明显缺陷就是存在单点故障 (SPOF),即如果节点挂了锁也就丢了,节点重启后就会有别的 client 抢锁成功,从而出现两个 client 同时拥有锁,且锁都未过期的情况。我们可以做什么来改变这点?
Master/Slave
既然存在单点故障,那就增加节点吧!利用 master/slave 的部署形式,master 挂了就将 slave 升级为 master。但 master 到 slave 的数据同步是异步执行的,这意味着 race condition 可能出现:
- client A 从 master 上获取锁
- master 在将 kv 同步到 slave 之前故障
- slave 称为 master
- client B 从新的 master 上获取锁,此时 A、B 都拥有锁
如果 master 已经将 kv 同步到 slave,则 fail-over 能够有效避免 SPOF 遇到的问题,因此综合考虑 master/slave 能够在某种程度上提高锁服务的容错能力。
也许我们可以使用 WAIT 命令,WAIT 的语义是等待所有 replicas 返回 ack,或者超时,而并非实现共识。master 与 slave 之间的数据同步可能刚好遇到长时间的网络故障导致 WAIT 超时,因此使用 WAIT 同样可以提高锁服务的容错能力,但额外的等待时间会降低锁服务的效率,可能得不偿失。
Redlock
Redlock 是 redis 的核心工程师 Salvatore Sanfilippo (antirez) 提出的基于多个 redis master 的分布式锁方案。假设整个系统中存在有 N (奇数,以 5 为例) 个相互独立的 master 节点,它们之间没有直接通信行为,一个 client 想要成功获取分布式锁,需要执行以下步骤:(详情请阅读 原文)
- 计算当前时间,精确到毫秒
- 顺序地向 N 个节点发送取锁请求 (单实例解决方案中的 Lock),N 个请求使用相同的 key 和 random value。每个请求的超时时间应该远远小于锁的过期时间,如 5~50 milliseconds 之于 10 seconds。如果遇到某个节点宕机或者请求超时后,client 会立即跳过该节点向下一个节点发送请求。
- 当且仅当 client 获得超过半数节点的 ack 后,同时取锁消耗的时间(利用步骤 1 的时间与当前时间对比)小于锁的过期时间,就认为取锁成功。
- 如果取锁成功,那么锁的实际超时时间 (vt)为原始超时时间与取锁消耗时间的差值,即经过 vt 后,其它的 client 就有可能取锁成功。
- 如果 client 未获得超过半数节点的 ack,则它会尝试向每个节点发送释放锁的请求。
为什么要按顺序取锁,而不并发取锁?并发取锁更容易触发脑裂 (split brain) 。
Asynchronous
这个算法是否依赖于时钟同步?答案是一定程度上依赖。首先 client 上的时钟漂移可能导致 TTL 计算不准确,其次有一种极端场景:
- client 1 从 A、B、C 节点上分别取锁成功,D、E 访问超时
- C 节点上的时钟发生漂移,导致锁过期
- client 2 从 C、D、E 节点上分别取锁成功,A、B 访问超时
- client 1 和 client 2 都认为自己取锁成功,违背了 safety 要求
Retry
取锁的过程可能出现 split brain,导致谁都抢不到锁,这时候如果所有 clients 都立即重试,split brain 很可能再次出现。解决方案也比较简单,使用随机退后的策略即可。
Debate
Redlock 问世后,引起了 Martin Kleppman 的 异议,而后 Salvatore Sanfilippo 又写了一篇 文章 反驳,可谓是理论与实践之间的一次碰撞,详情可点击链接查看原文,这里给出我的总结:
回到本文开头中的坐标系,Redlock 实际上是用效率换取正确性的一种分布式锁方案,它与其它方案之间的关系大致如下图所示:
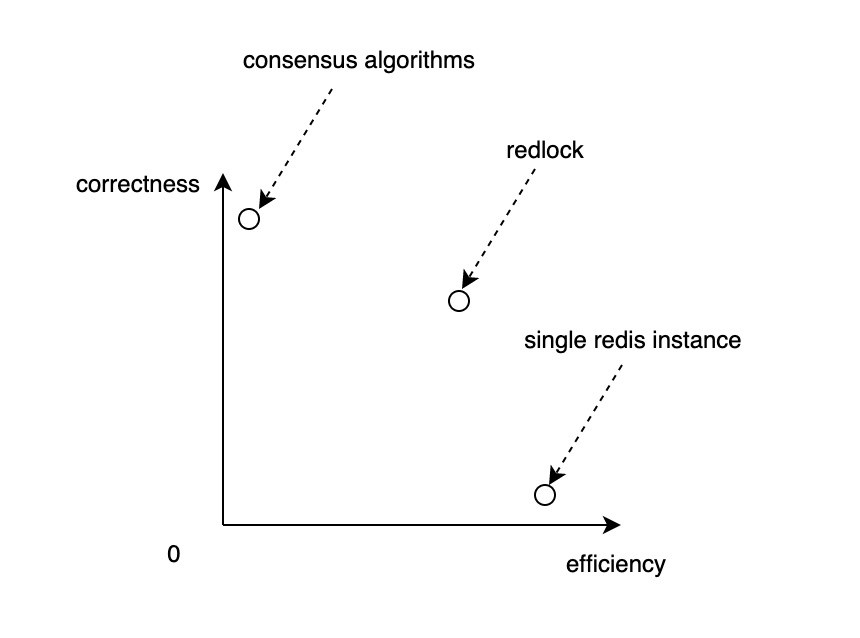
它不能保证分布式锁的 safety 性质。在实践中,我们通常要么就侧重效率,做好幂等,放弃要求锁服务绝对正确;要么就要求锁服务能保证绝对正确,牺牲效率,很难说服自己去使用一种折衷的解决方案。
Back to the Question
回到本文开篇的问题。
问:“如果某个 client 拿着锁执行任务时,redis 挂了怎么办?”
答:“看业务要求,大部分场景下挂了就随它去吧,通过主从、集群部署、甚至打开 fsync 、使用 WAIT 命令、实现 Redlock,都可以有限地增加锁服务的容错能力和可用性,但因为没有共识算法的支持,分布式锁的绝对正确仍然无法保证。如果不能牺牲正确性,就采用基于共识算法的分布式锁服务,但请务必关注具体业务场景的完整解决方案。“