The Anatomy of a Large-Scale Hypertextual Web Search Engine (1998)
引言
最近因为工作的关系接触 ElasticSearch,发现搜索引擎也是计算机应用的一个有意思的分支。于是通过 Freiburg 的 Information Retrieval 公开课开始系统地了解信息检索这个领域,感觉收获颇丰。周末一时兴起,上 Google Research 找到了 Google 的开山之作,近距离地感受一下 19800+ 引用量、造就如今 Google 万亿市值的这篇文章。
本文介绍会尽可能地忠于原文,但不是完全逐字逐句的翻译。
1. 简介
近年来,网络中的信息量和非专业的用户都在快速增长,为信息检索领域带来了新的挑战。从行为上看,人们更倾向于以门户网站,如 Yahoo,或搜索引擎为起点,利用网页间的链接来浏览所需信息。门户网站的索引来自于人工维护,聚合效果好、主观性高、维护成本高、改进速度慢,且通常不会覆盖小众话题。自动化的搜索引擎则相反,其它都满足,但聚合效果差,依赖于关键词匹配的检索方式返回的匹配项质量过低。一些广告商为了获取更多的流量,通过逆向工程来误导搜索引擎,使其结果靠前,进一步加剧问题的严重性。我们搭建了一个大型搜索引擎来当前系统的这些已知问题,它通过重度利用网页文本中的特殊结构来提供更高质量的检索结果。我们为这个系统取名为 Google,因为它是 googol (即 10100 ) 的常用拼写,后者的含义恰好与构建大型搜索引擎的目标体量相契合。
网络搜索引擎的扩张:1994 - 2000
为了跟上网络信息扩张的速度,搜索引擎技术也必须加速规模化。1994 年,World Wide Web Worm (WWWW),第一代网络搜索引擎 (web search engine) 之一,对 11 万网页或文件建立了索引;到了 1997 年末,行业领先的网络搜索引擎建立索引的数量已达到 200 万 (WebCrawler),甚至 1 亿 (Search Engine Watch)。可以预见这个数量在 2000 年将超过 10 亿。与此同时,网络上的搜索引擎处理的查询也在飞速增长。在 1994 年初,WWWW 大约每日需要处理 1500 次查询,到了 1997 年末,Altavista 已经声称自己每日处理的请求量达到 2 千万。同样可以预见,这个数量在 2000 年也将达到亿级。Google 的目标就是要提供相应规模、高质量的网络搜索服务。
Google: 与网络一同扩张
即便是搭建一个满足当前规模的网络搜索引擎也需要面对许多挑战,如:
- 高性能的网页抓取技术保证原始数据全而新
- 充足的存储空间用以存放索引和网页本身 (如果需要的话)
- 索引系统必须能够高效地处理百 G 级别的数据
- 查询必须能被快速处理,QPS 过千
随着网络信息的增长,这些挑战也将变得越来越难。然而,硬件性能的上升和成本的下降从另一个方面又抵消了一部分挑战难度。在设计 Google 的时候,我们同时考虑了网络信息的增长和技术的改进。Google 的设计能够在多方面支持更大规模的数据:
- 高效地使用存储空间存储索引
- 为高性能访问设计的数据结构
我们预期存储索引和文本的成本最终将被硬件的改进而抵消,这对 Google 这样的中心化、规模化的网络搜索引擎来说是利好消息。
设计目标
改善检索质量
我们设计的核心目标是改善网络搜索引擎的质量。在 1994 年,人们认为完整的索引意味着能搜索到任何信息。Best of the Web 1994 – Navigators 中提到,最好的导航服务应当能让人们轻松地找到所有进入网络中的信息。然而,到了 1997 年,情况变得大不一样,人们很快就发现索引的完整性仅仅是衡量查询结果质量的因素之一,原因在于许多垃圾信息占据搜索引擎返回结果的高位,导致人们常常无法快速找到有用的信息。讽刺的是,在 1997 年末,商业网络搜索引擎排名前四的网站中,以自己的网站名称为关键字进行搜索,仅有一个能在返回的前 10 条信息中找到自己 (此处应播放陶喆的《找自己》)。主要原因在于网页的数量增长了好几个数量级,但人们的查看能力并没有,他们仍然只会看前几十条搜索结果。在准确率与召回率中,Google 更看重前者。从最近的趋势上看,通过分析网页中的更多信息,网络搜索引擎以及其它应用的服务质量都能得到较高的改善,尤其是链接 (Link) 和链接文本 (Anchor),它们能够为相关性判断、质量过滤提供更多的信息。Google 在处理查询时也利用了链接和链接文本。
推进搜索引擎的学术研究
除了量上的快速增长,整个网络的商业化程度也正随着时间而增长。在 1993 年,仅有 1.5% 的网络服务挂在 .com 域名下,这个数字在 1997 年则达到了 60%。与此同时,搜索引擎也经历了从学术领域到商业领域的迁移。然而时至今日,各大搜索引擎开发团队公开的技术细节十分有限,多数用于市场宣传,内部实现对外界是黑魔法一般的存在。我们也希望通过 Google 将更多的开发实践和理解公开来推动学术研究的进步。
Google 的另外一个设计目标是要搭建让合理数量的学术界用户使用的系统。用户的行为数据能够帮助我们更好地改善搜索引擎本身。但由于通常这些数据具备商用价值,学术界用户很难获取相关信息用作研究。
Google 的最后一个设计目标是要基于海量网络数据,搭建支持更新颖研究的平台。为此,Google 将所有网页信息压缩存放,研究者登录后能够很容易的获取、处理海量网络数据,尝试有趣的研究活动。Google 上线后没多久,就已经有多篇已发表的论文利用了 Google 的数据库,还有许多未发表的工作也正紧锣密鼓地进行中。我们甚至希望能搭建类似 Spacelab 的环境,让研究人员、学生能够在海量数据上做任意有意思的实验。
2. 系统特性
Google 搜索结果的高准确率由两个特性来保证:
- 利用网页之间的链接关系来计算每个网页质量得分 (PageRank)
- 利用链接文本来改善搜索结果
PageRank: 为网页排序
网页与其之间的链接共同构成一张网,这些链接信息并没有被现存的网络搜索引擎利用。我们利用 5.18 亿链接数据建立这张网,并用它来快速地计算网页的 PageRank。PageRank 是一种利用引用关系来计算网页重要性的客观指标,它在很大程度上符合人们对于重要性的判断。
计算
学术文献引用的方式已经被一些网络搜索引擎用来估算页面重要性或质量。其最简单的方式就是看网页被引用或链接的次数。PageRank 沿着这个方向拓展思路,认为来自不同页面的引用的权重不同,被更高质量的网页引用权重应当更大。其定义如下:
假设网页 A 被 n 个页面引用,分别是 T1...Tn;参数 d 为取值范围在 [0,1] 的衰减因子,通常取值为 0.85;C(A) 为网页 A 外链的页面个数,那么 PageRank 可以由如下公式计算得到:
, (备注:如果这里显示有问题请看下面这张图) 实际上,PageRanks 可以被理解成所有网页的概率分布,所有网页的 PageRanks 加总值为 1。
![]()
PageRank,即 PR(A) 可以利用简单的迭代算法计算得到,它是网页链接矩阵的主特征向量 (principal eigenvector)。利用中型机,2600 万页面的 PageRank 可以在几个小时内计算得出。
直觉
PageRank 可以理解成是对用户行为的建模。随机选取一个用户,并为他选取一个随机的起始网页,然后让他通过网页的链接任意跳转到其它页面,但不后退到上一个页面,直到用户厌烦为止,然后再随机给一个起始网页,重复这个过程。那么这个随机用户访问到某页面的概率就是这个页面的 PageRank。衰减因子是用户感到厌烦后,放弃点击页面中的链接的概率。PageRank 的一个变种就是让衰减因子只对单个页面或一组页面生效,从而将用户的个人行为考虑在内,这种方式能防止一些 SEO 技术刻意误导搜索引擎,从而让广告页面获得高排名。更多关于 PageRank 的拓展技术请翻看 Page 98。
PageRank 的另一个直觉是:被越多的其它页面链接,被 PageRank 越高的页面链接,页面的 PageRank 就越高。被网络中越多的页面链接,证明该页面值得一看。同时,如果页面被像 Yahoo 主页这样的高质量页面链接,即使没有被其它页面引用,也值得一看;反过来说,如果页面本身质量较低,或者链接本身已经失效,那么 Yahoo 也不会保留对它的链接。PageRank 通过递归的方式地将权重合理地分配到网络中的页面上,反映出上述的特点。
链接文本
Google 特别利用了网页的链接文本。大多数搜索引擎都将链接文本与链接所在的网页关联,我们认为将链接文本与链接指向的页面关联更合理,理由如下:
- 链接文本通常描述的是链接指向的页面
- 链接文本指向的页面有时候并不是一个文本页面,它可能是图片、程序、甚至数据库
当然,这种方式也可能让搜索引擎返回链接已经失效、甚至从未存在过,但存在链接的页面。但我们可以通过结果排序,将这类结果排到搜索结果的末尾,使得此类问题的出现频率变得很低。
WWWW 采用这种方案的主要原因在于帮助用户检索非文本信息,同时利用更少的空间覆盖更多的网页;而 Google 采用这种方案则主要是为了更高质量的搜索结果。Google 为 2400 万网页中的 2.59 亿链接文本建立了索引。实践经验告诉我们,在海量数据场景上高效地利用链接文本也绝非易事。
其它特性
除了利用链接文本,Google 还拥有其他其它特性:
- 每个 hit (即 IR 中的 posting) 都包含词语所在的位置信息,以便在检索中利用关键词的接近程度 (proximity) 计算排序
- 保留一些视觉信息,如文字的字体大小,字体越大,其所占权重也越大
- 保留所有原始网页
3. 相关工作
网络信息检索的研究历史并不长。WWWW 是最早的网络搜索引擎之一,继 WWWW 之后出现了多个学术研究用的搜索引擎,它们中也有许多后来也转变成了商用。与网络信息的膨胀以及日益增长的搜索引擎的重要性相比,记载相关技术的文献则屈指可数。不过,业界存在许多围绕搜索引擎特定功能的工作,尤其是对商用引擎搜索结果后处理,产生小规模、个性化的搜索结果功能。值得一提的是,学术界存在大量基于控制良好的数据集的信息检索系统 (information retrieval system) 研究。
信息检索系统
信息检索系统的工作在多年前就已经开始,研究已经相当成熟。然而,大部分研究都是基于小规模、控制良好、同质的数据集,如科学论文数据集。即使是 Text Retrieval Conference [TREC 96] 所用的超大型语料 (Very Large Corpus) 基准数据集仅有 20 GB 大小,与我们抓取的 147 GB,2400 万网页数据相比算是小巫见大巫。在 TREC 数据集上表现良好的模型移植到互联网中并不能产生令人满意的结果。比如,在标准的向量空间模型 (vector space model) 中,查询语句和文档本身都被转化成基于词频的向量,查询问题即转化成在向量空间中找到与查询语句最为接近的文档。在网络环境中,这种策略倾向于返回长度较短的文档,通常文档内容就是在查询语句中增加少量的词语,而这常常不是用户想要的结果。我们认为标准的信息检索技术要在网络环境中真正应用,还有大量的扩展和改进工作需要完成。
网络数据集与控制良好的数据集的区别
网络中充斥着规模巨大的、完全无法控制的异构网页数据。网页文档内部的信息千变万化,即便是元信息也是如此。比如,网页内部的语言 (自然语言、编程语言)、词库 (邮箱地址、链接、邮政编码、手机号、产品编号)、格式 (文本、HTML、PDF、图片、音频、视频)、产生源 (人工生成、机器生成) 等;外部元信息包括网站的声誉、更新频率、质量、流行程度、使用方法以及引用信息。除了这些元信息外,即便是我们能够通过指标衡量的数据也存在很大的不同,比如一个网站的用户访问频率,对于搜索引擎来说,像 Yahoo 这样每天都有百万用户访问的网页,与一个十年才被访问一两次的历史页面,评价肯定不同。
另一个区别在于,网络中用户的行为完全不可控。可以通过恶意的 SEO 技术来误导搜索引擎也成为日益严重的问题,即便是网页中没有向用户直接展示的信息也可能被恶意用户利用。对于基于控制良好的数据集的传统信息检索系统来说,这个问题几乎未被考虑。
4. 系统架构
本节首先介绍整体架构 (high-level design),然后详细讨论一些重要的数据结构,最后深入介绍各个服务模块,如爬虫、索引、检索等。
Google 架构总览
整体架构如下图所示:
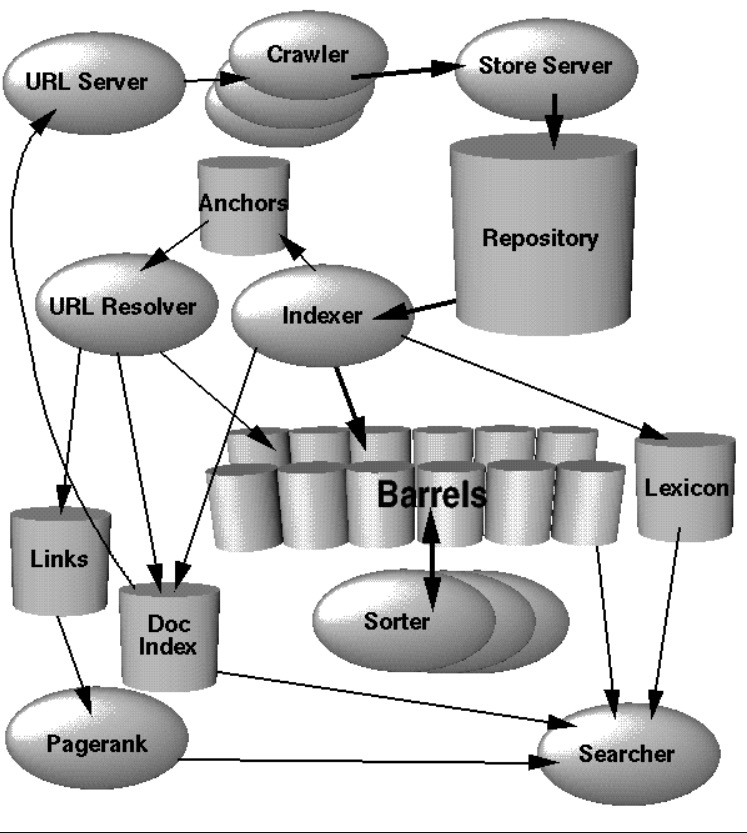
在 Google 中,URL 服务负责提供 URL 列表给爬虫服务,爬虫 (crawlers) 服务则以这些页面为起点,不断进行爬取操作。被爬取的网页会被传输给存储 (Store) 服务,存储服务负责将网页压缩,然后放入仓库 (Repository) 中。每个新的网页都会被分配唯一标识,即 docID。
建立索引的过程由索引器 (indexer) 和排序器 (sorter) 共同完成。索引器的工作可以分为多步:
- 从仓库中读取网页,解压缩然后再解析 (parse) 页面数据
- 将每个网页文档中的文本加以提炼,转化成 hits 数据结构,每个 hit 记录出现的单词、单词出现的位置、字体的大小和大小写情况;同时,也将解析出来的网页链接信息放入 anchor 文件中,其中链接信息包含每个链接的来源网页、目标网页及链接文本
- 将所有 hits 分发到不同的桶 (barrels) 中,并建立部分排序的正排索引 (partially sorted forward index)。这里,所谓正排索引就是 docID 到 word 列表的映射,这些正排索引所在的桶也被称为正向桶 (forward barrels)。
URL Resolver 读取 anchor 文件中的链接,将其从相对 URL 转化成绝对 URL,并生成相应的 docID,其中链接文本和 docID 被放入正排索引中。URL Resolver 也将链接信息放入链接 (Links) 数据库中,后者将被用于为所有网页计算 PageRank。
排序器从正排桶中读取正排索引,将其通过 wordID 转化成倒排索引 (inverted index),即 wordID 到 docID 列表的映射。这部分工作在原地完成,仅仅需要一小部分临时空间即可,这时我们也称存放倒排索引的桶为反向桶 (inverted barrel)。排序器和索引器会将词语扔到 Lexicon 服务中,构成全局的词表,后者会在检索服务 (Searcher) 中被用到。
检索服务结合词表、倒排索引、PageRank 以及 DocIndex,向外提供网页检索的功能。
主要的数据结构
Google 数据结构主要是为了优化数据的抓取、索引和搜索成本而设计。尽管近年来,CPU 和 I/O 吞吐能力都得到了极大的改善,但磁盘寻道仍然需要 10ms 的时间。Google 设计数据结构和算法时,在能避免磁盘读取的地方都尽可能地避免。
BigFiles
BigFiles 是基于多个文件系统提供虚拟文件系统的抽象,每个虚拟文件的地址可以用一个 int64 数字唯一确定。虚拟文件在多个文件系统上的分配逻辑由 BigFiles 内部自动处理,用户对此并无直接感知。BigFiles 也会负责分配和释放文件句柄,同时提供文件压缩功能支持。
Repository
仓库中存储着每个网页的完整 HTML 数据,并使用 zlib 压缩。在压缩技术的选择中,需要考虑压缩速度和压缩率之间的权衡。相对于 zlib 3:1 的压缩率,bzip 的压缩率能达到 4:1,但 zlib 在速度上的优势让我们选择它。在仓库中,所有文档依次存放,每个文档的头部存储着 docID、长度、URL 等元信息,如下图所示:

文档的读取不需要额外获取其它服务的数据,这对数据的一致性和功能开发都提供了便利。我们可以从仓库中的数据和抓取的错误日志出发,重新构建其它任何数据结构。
Document Index
Document Index 保存着每个网页文档的元信息,是一个定长的 ISAM (Index sequential access mode) 索引,按照 docID 排序,这些信息包含当前的文档状态、文档数据在仓库中的地址、文档 checksum 和各式各样的统计值。如果文档已经被爬取过,那么还包含一个指向变长的 docinfo 文件的指针,文件中包含着文档的 URL 和标题,如果尚未被爬取,则该指针指向的是相应的 URL list。这种设计就是为了在一次磁盘读取中获取所需数据 (定长索引支持随机访问)。
除此之外,还有一个文件数据用来将 URL 转换成 docID,文件内部存储着 URL checksum 和 docID 间的关系,整个字典按照 URL checksum 排序。为了查到某个 URL 对应的 docID,就直接计算一下 URL 的 checksum,然后在文件中使用二分查找。我们还可以批量地为 URL 生成 docID,然后将批处理后的文件与原文件合并。URL resolver 正是利用了这种方案将 URL 转化成 docID。
Lexicon
相对于以前的系统,Google 词表 (Lexicon) 的一大变化就是它的词表可以完整地装进拥有 256MB 内存的机器。当前版本的词表共包含 1400 万个单词,其中一些生僻词被排除在外。词表的实现由两部分构成,利用 null 拼接起来的单词列表,和一个指针哈希表。为了提供更丰富的功能,单词列表中还包含一些附加信息,这些信息的具体内容不在本文探讨的范围内。
Hit Lists
单个 Hit 对应着某个单词在某个文档中某次出现的信息,如位置、字体、大小写状态;而一个 Hit List 对应着某个单词在单个文档中多次出现的信息列表,在信息检索文献中 Hit 也称为 Posting。Hit List 占用了正排索引和倒排索引的大部分空间,正因如此,它的数据结构设计也应当尽量高效。Google 在设计时考虑了 Hit 的多种编码方案:
- simple encoding:整数三元组 (a triple of integers)
- compact encoding:手动设计的 bit 分配方案
- Huffman coding
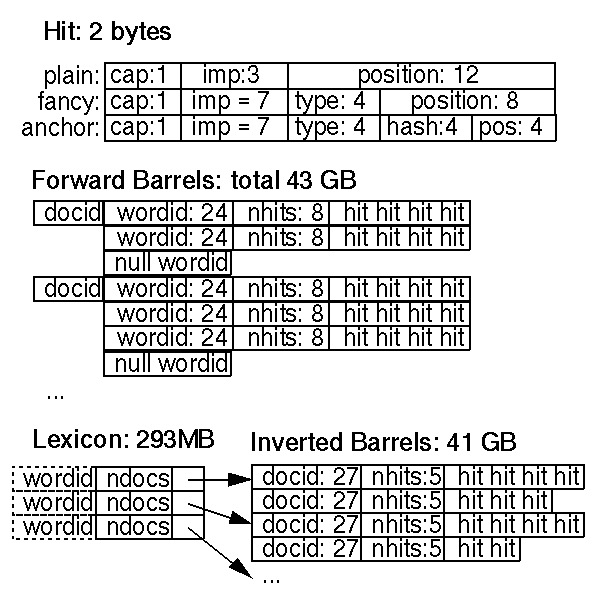
最终我们选择 compact encoding,原因在于它比 simple encoding 更节省空间,比 Huffman coding 实现需要的位运算量更小,更节省 CPU。Hit List 的 compact encoding 具体例子如本节末尾的图片所示:
compact encoding 为每个 hit 分配 2 字节。Google 定义了两种 hits,fancy hits 和 plain hits。Fancy hits 包含出现在 URL、标题、链接文本和 HTML meta 标签中的信息;Plain hits 则包含剩下的文本信息。一个 plain hit 由capitalization bit (标识是否大小写的比特位)、字体大小以及位置信息构成,其中偏移超过 4095 的位置统一由 4096 来标识。字体大小占据 3 bits 空间,其中 111 被保留用作表示 fancy hit,因此实际仅支持 7 种字体大小。一个 fancy hit 由 capitalization bit,类型标识和位置信息构成。对于 anchor 类型的 fancy hit,位置信息进一步被划分为两部分,一部分 (4 bits) 标识词语在链接文本中的位置,另一部分存储链接文本所在 docID 的哈希值 (文中没有体现这个哈希值的作用,但大概是方便利用 hit 信息反查 docID,毕竟 4 bit 只能缩小查询范围)。由于每个链接文本的词语并不多,这种存储 anchor fancy hit 的方案可以支持基于链接文本的短语搜索 (phrase searching)。对于字体大小,Google 主要利用了字体在整个文档中的相对大小,因为对于两个一模一样的文档,我们不能因为其中一个字体更大而给它更高的分数。
在每个 hit list 之前会记录这个 list 的长度。为了节省空间,在正排索引中,list 的长度信息与 wordID 共同存放;在倒排索引中,list 的长度与 docID 共同存放。如果长度较大,与 wordID 和 docID 共同存放空间不足,则会利用一个 escape code 标识,并利用接下来的两个字节标识其真正长度。
Forward Index
正排索引存储在一组 (64 个) 桶中,每个桶负责存储固定范围的 wordID。如果一个文档包含的词语落在某个特定桶的范围内,那个 docID 也将被记录到桶中,并在其后排列着这个文档对应的所有范围内词语的 hit lists。由于每个 docID 可能会被存储到多个桶中,因此需要耗费少量额外的存储资源,但这点资源能够换取排序器在索引阶段的时间消耗和逻辑复杂度。在每个 docID 的 wordID 列表中,为了节省空间,我们只存储了最小的 wordID 和其它 wordID 与最小值的差值,这样每个 wordID 只需要 24 bits 的存储空间,留下 8 bits 用来存储 hit list 的长度信息。
Inverted Index
倒排索引和正排索引一样,存储在同一组桶中,由排序器负责生成。针对每个合法的 wordID,词表中都会存放一个指针,指向对应桶中的 doclist,每个 doc 中包含相应的 hit list。doclist 表示该单词在所有文档中的出现信息。
这里值得关注的一个问题是:在 doclist 中不同的文档之间如何排序?一种简单的方案是按照 docID 排序存储,这种方案对于多词查询合并 (merge) doclist 的操作十分友好;另一种选择是按照单词在文档中出现的模式定制化排序。这使得单个词语查询非常容易,也可以让多词查询的结果文档尽量排序靠前,但合并的过程将变得不友好。Google 选择了一个折衷的方案,保留两组倒排索引,一组用于存放 title hits 或者 anchor hits,可以称之为短文本倒排索引,其容器为短反向桶 (short barrels),另一组用于存放普通 hits,可以称之为全文倒排索引 (full text inverted index),其容器为全反向桶 (full barrels)。在搜索时,先检查第一组索引,如果结果不足,再到第二组索引中查询。文章并未提及两组索引内部使用哪种排列方式,个人认为也许可以在短文本索引中按 docID 排序,在全文索引中可定制的利用模式排序,从而得到更快的响应速度。
爬取网络数据
运行和维护网页爬虫很有挑战性。除了很取巧的性能和可靠性优化,还有更重要的社会问题 (social issues)。由于爬虫需要与成千上万的外部服务交互,这些外部服务都在爬虫的控制之外爬虫几乎是最难做到健壮的系统。
为了能够爬取亿级的网页数据,Google 搭建了高性能的分布式爬虫系统。由一个单独的 URL server 向若干个爬虫服务 (通常是 3) 提供 URL 抓取列表。URL server 和爬虫服务都是用 Python 实现 (大概是因为逻辑复杂,性能瓶颈在网络 I/O 的缘故吧)。每个爬虫服务维持大概 300 个连接,这对于快速爬取网页是十分必要的,在峰值速度上,同时开启 4 个实例,这套爬虫系统每秒可以爬取 100 个网页,约 600K 数据。性能压力主要体现在 DNS 查询上,因此每个实例都会维护着自己的 DNS 缓存,避免每次访问网页都执行一次 DNS 查询。每个连接可以处于多个状态,如 DNS 查询、与 host 建连中、发送请求中、接收响应中等等,这也让爬虫系统变得更加复杂。爬虫服务内部使用 asynchronous I/O 来管理事件,并利用多个队列来管理连接的状态。
运行和维护这个量级的爬虫服务也会招来无数的邮件和电话。许多互联网用户并不知道什么是爬虫,因此他们总会打电话来问:“我发现你翻看了我们的网站,觉得我们网站怎么样?” 也有一些用户并不知道 robots 协议 (robots exclusion protocol),认为他们只要在网页上声明 “The page is copyrighted and should not be indexed”,爬虫看到后就会停止爬取,显然要让爬虫理解自然语言并非易事。爬虫系统涉及海量数据,意外情况自然不会少。例如,当我们的系统尝试抓取在线游戏页面时,就会导致正在进行游戏的用户看到许多无意义的消息,不过这个问题不大,很容易解决,只不过直到我们爬取了数千万的网页后才发现它。正因为网页和服务的多样性存在,我们只能在线上环境测试爬虫,而一个页面的问题就有可能导致爬虫崩溃,甚至造成预期之外的、不正确的行为。因此,大量的资源需要投入到解决系统健壮性和理解用户反馈、解决用户问题上。
构建网络数据索引
1. Parsing
一个为整个网络环境设计的解析器需要解决无数种可能的错误,如 HTML tags 的书写错误、tag 之间大量无用占位数据、非 ASCII 字符、几百层嵌套等各种超乎想象场景。为了达到最快速度,我们没有使用 YACC 生成 CFG (context-free grammar),而是使用 flex 生成词法分析器后自己实现语法分析逻辑。开发一个满足性能和健壮性要求的解析器也耗费了我们大量精力。
2. Indexing Documents into Barrels
每个网页被解析后,里面的每个单词都会利用内存中的词表转化成对应的 wordID,然后根据不同桶对应的固定范围将网页数据分散到多个桶中。出现词表中不存在的单词时会记录相应的日志到文件中。一旦单词背转化成 wordID,它在网页文档中的出现信息就会被转化成相应的 hit lists,写入正向桶中。本阶段并行的技术难点在于词表共享。我们采用的方案是在每个排序器的内存中维持一份 1400 万的固定词表,然后将所有词表外的单词信息打入统一的日志,由单独的一个兜底排序器负责处理。
3. Sorting
为了生成倒排索引,排序器需要对每个正向桶按照 wordID 来生成短文本倒排索引和全文倒排索引。整个过程是线性地、一个一个地处理每个桶中的数据,所需的临时空间并不大。我们可以通过多个 sorter 并行处理单个桶内的不同分片的数据来提高效率。由于桶里的数据不能全部装进内存,排序器需要根据 wordID 和 docID 将数据划分成多个分片后再读入内存处理。
搜索
搜索的目的是高效地提供高质量的查询结果。许多大型商业搜索引擎在性能上都有很大的进步,因此我们把研究重心更多地放在质量上,同时保证解决方案可以规模化,Google 的查询处理流程如下:
- 解析查询语句
- 将语句中的单词转化成 wordID
- 在短反向桶中找到单词对应的 doclist
- 找到匹配所有词语的文档
- 计算该文档的排序得分 (rank)
- 如果任何单词在短反向桶中对应的 doclist 已经遍历完毕,则继续找到该单词在全文反向桶上对应的 doclist,重复步骤 4
- 如果所有单词对应的短反向桶都尚未遍历完,则重复步骤 4
- 如果某单词已经全部遍历完毕,则结束,返回排序后的 topk 文档即可。
为了限制响应时间,一旦检索出的网页数量达到固定数量 (当前值为 4 万) 后,搜索过程就会自动来到步骤 8,通过牺牲召回率换取性能。通过 PageRank 来给 hits 排序能有效地提高召回率,即让目标网页尽量出现在前 4 万条记录中。
排序系统
与其它搜索引擎相比,Google 利用更丰富的网页信息,每个 hit 都包含位置、字体和大小写信息,同时也考虑了链接文本以及网页的 PageRank。将所有这些信息结合起来并不容易,结合的过程中我们尽量不让任何一个因素产生过大的影响。
首先考虑最简单的场景,单个词语查询。为了给单个词语的查询结果排序,Google 将不同种 hit 分开考虑 (标题、链接文本、URL、大字体文本、普通文本),每种类型的 hit 都有相应的权重设置,构成类型权重 (type-weights) 向量。找到单词对应的 hitlist 后,Google 会计算其中每种类型 hit 的数量,计算计数权重 (count-weights),计数权重与每种 hit 的绝对数量并非呈现线性关系,而是先随着绝对数量线性增长,然后逐渐停止,超过阈值后则不再考虑。最后将类型权重与计数权重做点积,得到网页的 IR (information retrieval) 得分。最终结合 IR 得分与 PageRank 得到网页的最终得分。
多词查询场景更加复杂。我们需要同时扫描多个单词的 hit list,并且多个词在文档中举例更近的网页要给与更高的权重。来自不同 hit lists 的 hits 需要尽量按照其在文档中相邻的距离来匹配。针对每组匹配的 hits,需要计算不同词语的接近程度 (proximity),接近程度被分为 10 档,从短语匹配 (phrase match),即完全相邻,到完全不相邻 (not even close)。在计数时,不仅需要考虑 hit 类型,还需要考虑接近程度,每组类型和接近程度都有固定的权重,称为 type-prox-weight。最终通过计算计数权重 (count-weights) 和类型距离权重 (type-prox-weight) 的点积得到 IR 得分。在 debug 模式下,这些信息都会被打印出来,对开发过程帮助极大。
反馈
我们的排序机制有许多参数,如类型权重、类型距离权重。合理地设置这些参数的值有点黑魔法的味道。为了找到更好的参数值,我们也在搜索引擎中建立了用户反馈机制。一个被信任的用户可以帮助我们标记搜索结果的质量,并反馈给服务端。这些反馈信息会被保存记录,帮助我们调整排序函数的参数。尽管目前这样的机制并不完美,但它也在一定程度上帮助我们理解参数变化对排序效果的影响。
按:本文以介绍核心架构和原理为主,由于文章发表的年代久远,性能结果没有太大的参考价值,相应的部分就不作介绍,结论和致谢部分也忽略,有兴趣可以翻看原文。