用 LSM Tree 实现一个键值数据库 —— GopherConf 2017 演讲笔记
Background
数据库中的各种奇技淫巧,实际上都来自于内存与磁盘的读写模式和性能区别。
数据库中的各种奇技淫巧,实际上都来自于内存与磁盘的读写模式和性能区别。
在计算机系统设计实践中,我们常常会遇到下图所示架构:
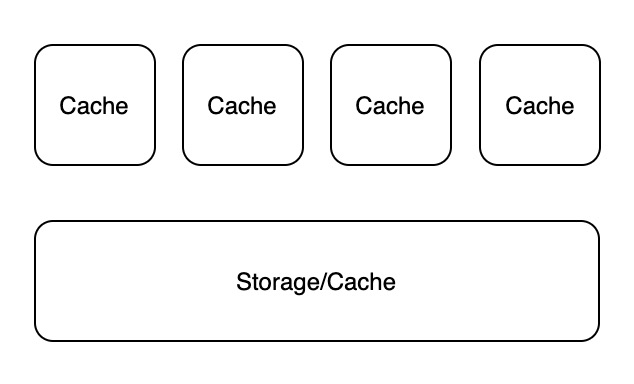
为了解决单个存储器读吞吐无法满足要求的问题,常常需要在存储器上面增加一个或多个缓存。但由于相同的数据被复制到一个或多个地方,就容易引发数据一致性问题。
论文作者的贡献主要包含两部分:Consistent Hashing 和 Random Trees。Consistent Hashing 主要用于解决分布式哈希表 (Distributed Hash Table, DHT) 的桶增减带来的重新哈希问题;Random Trees 主要用于分布式缓存中的热点问题,它利用了 Consistent Hashing。下文主要关注 Consistent Hashing。
Linear Hashing 和 Spiral Storage 是两种动态哈希算法。这两种算法最初都是为了优化外部存储 (secondary/external storage) 数据访问而设计的。本文将这两种算法引入到内存中,即键值数据可以一次性读入内存的场景,对比、分析二者之间,以及与其它动态哈希算法的性能。实验结果表明:Linear Hashing 的性能上要优于 Spiral Storage,实现难度上要小于 Spiral Storage。其它纳入对比范围的动态哈希算法包括 Unbalanced Binary Tree 以及支持周期性 rehashing 版本的 Double Hashing。Linear Hashing 的查询时间与 Double Hashing 相当,同时远远优于 Unbalanced Binary Tree,即使在 tree 很小的场景上也如此;在载入键值数据的表现上,三者相当。总体而言,Linear Hashing 是一个简单、高效的动态哈希算法,非常适用于键空间未知的场景。
缓存置换算法 (Cache Eviction Algorithm) 在操作系统、数据库以及其它系统中被广泛用于缓存置换模块,当缓存空间不足时,它利用局部性原理 (Principle of Locality) 预测未来数据的使用模式,将最不可能被访问的数据清出从而提高缓存命中率。目前已经存在的缓存置换算法包括 MRU (Most Recently Used)、MFU (Most Frequently Used)、LRU (Least Recently Used) 以及 LFU (Least Frequently Used) 等。每个算法都有其各自的适用场景。到目前为止,应用范围最广的是 LRU,主要原因在于 LRU 贴近大多数应用的实际负载模式 (workloads),同时 LRU 拥有 O(1) 时间复杂度的成熟实现方案。与 LRU 类似,LFU 同样与大多数应用的负载模式相近,但目前 LFU 最佳实现方案的时间复杂度是O(log2n) ,不如 LRU。本文,我们提出一种同样达到 O(1) 时间复杂度的 LFU 实现方案,它支持的操作包括插入、访问以及删除。
本文是分布式系统理论的开山鼻祖、2013 年图灵奖获得者 Lamport 的成名作,也是分布式计算领域杰出论文最佳影响力奖 Dijkstra Prize 的第一篇论文,高达 11692 的引用量(截至 2019/12/08)足以证明其广泛的影响力:

本文主要讨论 3 个话题:
早在 2008 年,Google 就已开始分布式调用链追踪的工作,经过两年的打磨后,Dapper 系统问世,并通过这篇文章将其设计公之于众。遗憾的是,Dapper 并不是开源项目,但它的设计理念依然深刻影响到后来的 Jaeger、Zipkin 等开源分布式追踪项目,以及相关的标准 Opentracing、OpenTelemetry。
本文不是原文的精准翻译,而是一次重述和简述,旨在记录分布式调用链追踪要解决的核心问题和潜在解决方案。
在大型微服务架构中,服务监控和实时分析需要大量的时序数据。存储这些时序数据最高效的方案就是使用时序数据库 (TSDB)。设计时序数据库的重要挑战之一便是在效率、扩展性和可靠性中找到平衡。